
When people talk about AI security, the conversation usually goes straight to prompt injection, jailbreaks, data leakage, or model hallucinations. These are real problems and deserve the attention they get. But after working on production AI systems and doing security reviews on LLM-based features, I've noticed there is another attack surface that almost no one models properly: Tokenization
It sounds like an internal implementation detail, something only ML engineers need to worry about, but from a security perspective, tokenization sits right at the boundary between user input and model behavior. And anything that sits on a boundary is a potential attack surface.
If you are building AI systems and you are not thinking about how to tokenize input, you are not looking at the real system the model sees.
What does tokenization actually mean in practice?
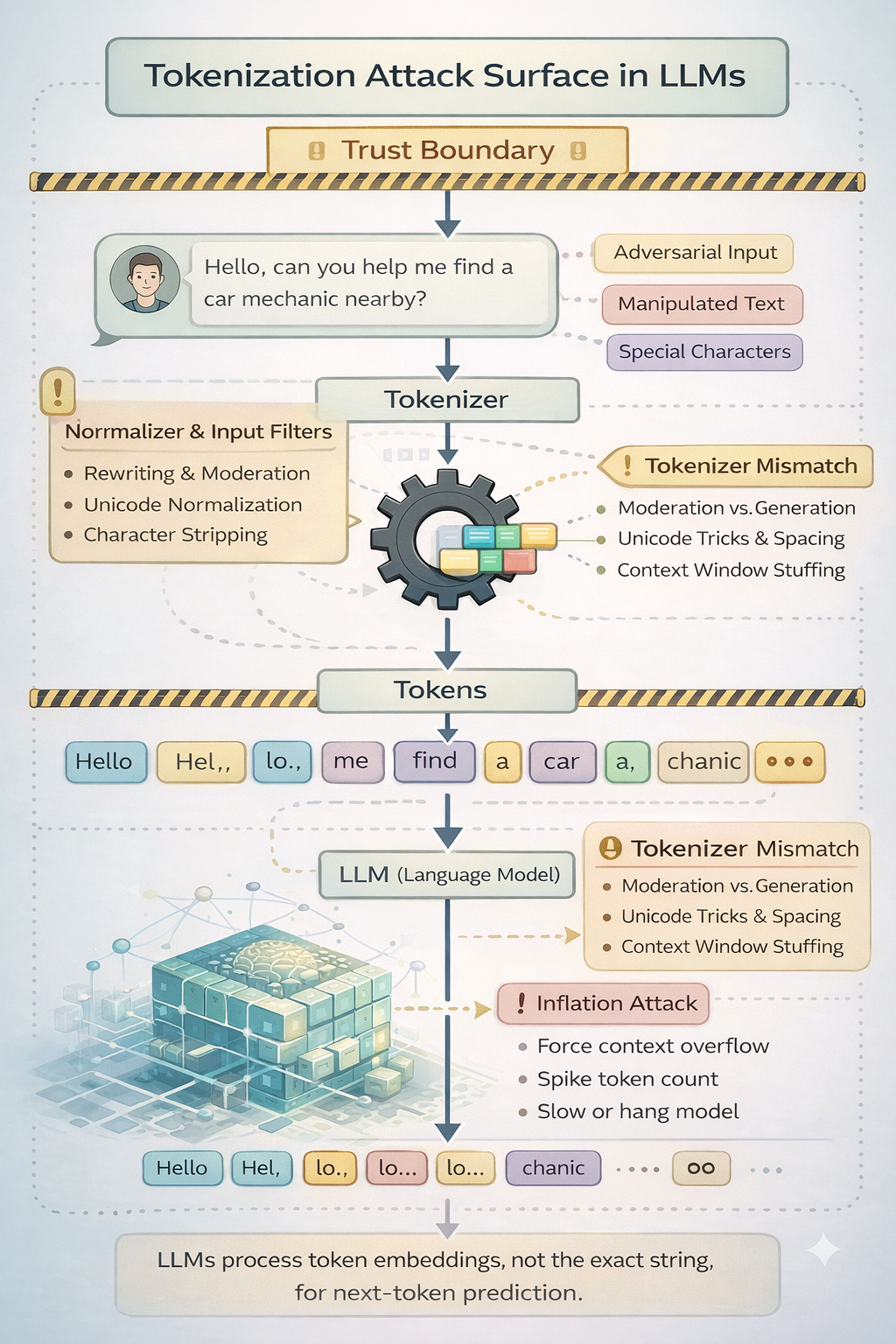
Large Language Models (LLMs) do not read text the way humans do. They do not see words, sentences, or paragraphs. The input goes through a tokenizer, which converts the text into small pieces called tokens. Now, depending on the tokenizer, a single word might become multiple tokens, or multiple characters might become one token. Some common tokenization algorithms are BPE, Wordpiece, or SentencePiece, which split text in ways that are optimized for training models and not for human readability.
For example, a word like ‘authentication’ might be split into several smaller tokens. Sometimes, even spaces, punctuation, or special Unicode characters become separate tokens.
The important security insight here is simple: The model reasons over tokens, not over the exact string that a human sees, and that gap between what the user sees and what the model processes is where attacks start to appear.
What is a tokenization attack?
A tokenization attack is when someone deliberately crafts input to manipulate how the text gets split into tokens. The goal is usually to bypass filters, break guardrails, confuse the model, or push important instructions out of context. From outside, the input might look harmless, but once it is tokenized, the model may see something very different. This is similar to classic encoding attacks in web security, where the server and the filter interpret the same input differently. In AI systems, the tokenizer becomes part of that interpretation layer. And if different parts of your system interpret input differently, attackers will find a way to exploit it.
For example, imagine a moderation system blocks the word ‘malware’. An attacker could insert invisible Unicode characters or spacing that bypasses string matching but still tokenizes to the same meaning for the model. If the moderation layer and the model tokenizer are not aligned, the guardrail can be bypassed.
Why does this matter for real AI products?
Tokenization attacks are not just theoretical. They matter in any system where user input goes directly into a model. This includes copilots, chat interfaces, RAG pipelines, code assistants, agent workflows, and internal AI tools. If the system relies on moderation, prompt rules, or structured output, tokenization behavior can affect it all.
It also affects cost and reliability. Token count determines billing, latency, and sometimes even whether a request succeeds. If someone can manipulate tokenization, they can influence all of those things. Most application security teams are used to thinking about input validation, encoding, and parsing. Tokenization is the same kind of problem, just a new layer in the stack.
How I think about tokenization during security reviews
When I review an AI system, I always ask a few basic questions.
Are moderation and inference using the same tokenizer, or are they looking at different representations of the input?
Is the input normalized before validation, especially for Unicode and invisible characters?
What happens when the token limit is reached, and which part of the prompt gets removed first?
Is there any monitoring for unusual token usage, like sudden spikes or highly fragmented inputs?
And most importantly, has anyone actually tested adversarial inputs through the real tokenizer instead of just looking at the raw text?
These questions sound simple, but they often uncover gaps that were never considered during design.
Defensive practices that actually help
The first thing I recommend is normalizing the input before doing any filtering or moderation, and that means applying consistent Unicode normalization and stripping characters that should not be there.
Second, moderation, guardrails, and inference should operate on the same tokenized representation whenever possible. If different layers see different versions of the input, you are creating room for bypasses.
Third, enforce limits based on tokens, not just on characters or requests. Token count is what the model actually cares about.
Fourth, reserve part of the context window for system prompts and safety instructions. Do not let user input silently push them out.
Finally, make sure to test the tokenizer itself. Try unusual characters, long inputs, and strange spacing. Treat the tokenizer like any other parser that needs to be hardened.
The bigger shift in AI security
As AI systems become more complex, the attack surface is moving lower in the stack. It is no longer just about prompts. It is about how input is encoded, how context is built, and how the model actually sees the data. Tokenization sits right at the boundary.
In traditional AppSec, we learned that parsing bugs lead to real vulnerabilities. In AI systems, tokenization plays a similar role. So now, when I review an AI feature, I do not just ask whether the model can be jail-broken. I ask a simpler question first: How does this input tokenize? Because that is usually where the real problem starts.
Note: This post is intended as an introduction to tokenization attacks, so the discussion is kept at a high level and does not go into deep technical detail.